



Language models, oh so grand,
Taking the world by storm in demand,
VC firms and startups all in a daze,
As AI technology continues to blaze.
© ChatGPT when prompted to “write a short poem about how large language models are taking the world by storm and causing VC firms and startups to panic.”
These zero-shot reasoners have taken the industry by storm. Everyone is experiencing the LLM FOMO. Companies are trying to figure out how to implement a large language model into their product (even if that’s just the OpenAI API), while VCs are looking into usage trends and brainstorming how to name the fields of AI that encompass the creation, usage, or maintenance of large language models (e.g., LLMOps, FOMO, or #FMLops, as we lovingly call the field), or debate if prompt engineering will be a career of choice soon.
Indeed, with the rapid commercialization of the technology, it seems like the marginal returns for each company looking to adopt the technology will be higher if they decide to train a custom LLM based on a vertical use case (and, as an extension, proprietary data). Domain-specific LLMs, after all, outperform general LLMs like GPT-3, Dall-E, etc.
As common models get commoditized, it all comes down to two factors:
What data do you own? Data, not its size, is now the active constraint on language modeling performance (and returns on new data are enormous). Large language models are trained on pretty impressive datasets. When you combine GitHub, Arxiv, Books3, and the entire crawlable web data, it amounts to around 3.2 trillion tokens or about 1.6 times the size of the MassiveText dataset! However, ML specialists should prioritize domain-specific corpora to enhance model performance in a specific vertical. By using a domain-specific corpus, companies achieve more accurate and effective models that can interpret domain-specific language much better. For example, if a healthcare company uses a healthcare-specific corpus, the model will be trained on medical terminology, making it more effective in understanding and processing medical text.
How fast can you spin up your data flywheel? It all comes down to who built the best data flywheel: the data engine for iterated data acquisition, re-training, evaluation, deployment, and telemetry. More importantly, whoever spins it the fastest (and cheapest, since you don’t see many companies casually walking around with a $10B injection from MSFT).

But how can you achieve this? This article will cover common issues arising when you train large-scale (>XB parameters) LLMs and how to address them to utilize your GPUs fully.
The ABC of LLMs: What are Large Language Models?
Large language models are a type of artificial intelligence system that utilize deep learning algorithms to generate and interpret human language. They are trained on massive amounts of text (more recently - multimodal) data and use that information to answer questions, summarize text, translate languages (Open GPT-3, Cohere, and Anthropic), and generate videos (Microsoft X-Clip), audio (OpenAI Whisper), or images (Stable Diffusion by Stability AI, Open AI’s Dall-E).
LLMs are not all-powerful. You can think of Chat-GPT as a studious English language student. They might have mastered the art of expression but not causal reasoning. Their performance is average (compared to other people), on average. Nonetheless, these models can generate high-quality natural language output, making them highly valuable for various applications in multimedia, healthcare, marketing, and beyond.
However, their size and computational requirements make them more challenging to deploy, and there are concerns about the ethical and societal implications of using these models. For instance, they may hallucinate a truthful-looking answer (deceitful enough to get overlooked by even the Google Marketing team). In the next section, we will cover the common hurdles for LLM adoption and how to fix them by setting up a “data flywheel” to fine-tune and correct mistakes.
What is a data flywheel?
A data flywheel refers to a self-reinforcing cycle in which data is acquired and ingested into the machine learning model training process, and the subsequent model performance is improved. This concept is associated with successful machine learning implementations at companies like Tesla and Netflix.
The process starts with collecting and curating large amounts of high-quality machine learning datasets (e.g., Tesla car cameras recording the car surroundings), which are then used to train ML models (e.g., for lane detection). These models are deployed to automate decision-making and make predictions. As they are used after deployment, they create more real-world data, which can be used to refine the models and enhance their performance. This leads to better predictions and more data through more usage, thereby completing the “data flywheel.” A next-gen data flywheel might also move beyond annotation, as the more and the faster high-quality data you acquire and process, the better your LLMs will be.
For more information on the data flywheel, check out Andrej Karpathy's talk on it and the following work from Amazon’s team on continual learning.
What issues arise when training LLMs?
- Data storage and retrieval bottleneck: It’s no secret that LLMs require massive amounts of data. This data needs to be stored and retrieved efficiently to ensure that the model can be trained in a reasonable amount of time. Sadly, some of the status quo storage and retrieval methods are too outdated to keep up with the demands of these models. The challenge is further exacerbated if the data is stored in multiple locations, is in different formats, or is simply too large to be efficiently stored in memory…
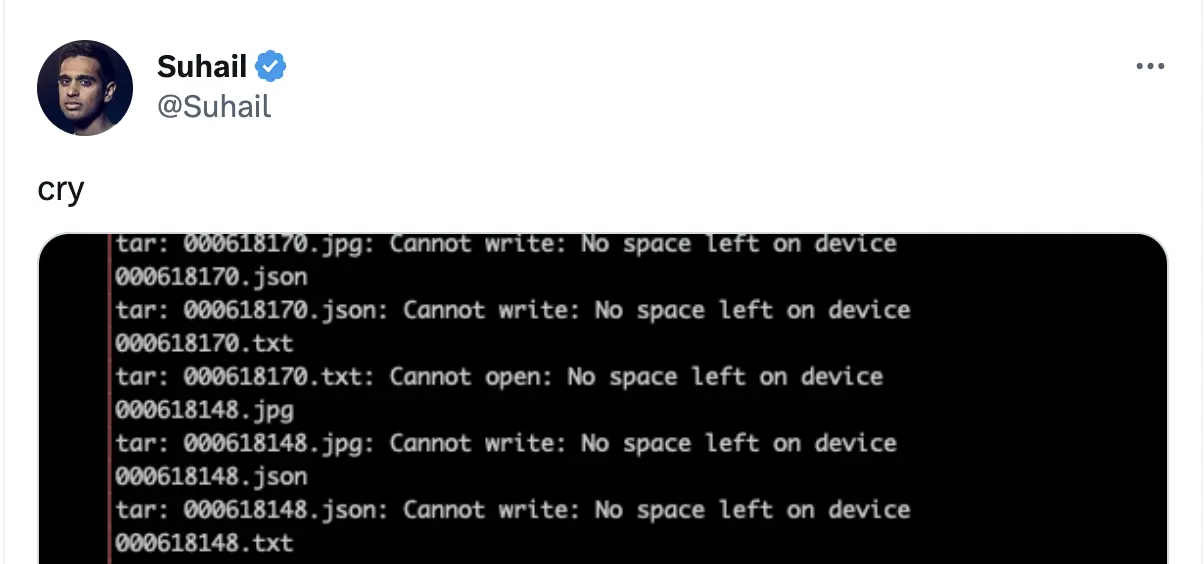
Don’t take my word for it. Here’s what a fellow YC founder in the generative AI space had to say about this bottleneck.
On the retrieval part of the issue, it’s essential to quickly kill the process and refrain from training a model on buggy data for weeks to hit a snag once you’ve burnt many compute credits.
Both issues can be resolved with a data lake optimized for deep learning (or Deep Lake, as we call it). Deep Lake maintains the benefits of a vanilla data lake with one key difference: it stores complex data, such as images, videos, annotations, as well as tabular data, in the form of tensors and rapidly streams the data over the network to (a) Tensor Query Language, (b) in-browser visualization engine, or © deep learning frameworks without sacrificing GPU utilization. Datasets stored in Deep Lake can be accessed from PyTorch and TensorFlow and integrated with numerous MLOps tools.
As a result, you can store data on the cloud and stream it efficiently to test the model performance locally before scaling it to the cloud. Secondly, thanks to streaming, you can unify data from disparate sources (in a standardized format explicitly built for deep learning). Lastly, you can immediately start the training process and kill buggy processes, not wasting money on idle GPU time.
- Data quality bottleneck. In a tale as old as time, your ML model is as good as your data (who needs a… rusty… CLIP?!). Language models can be trained on data heavily biased towards a particular demographic or group (thus possibly making unfair predictions when dealing with individuals from underrepresented groups). This leads to incorrect predictions and perpetuates harmful societal stereotypes and biases.
For instance, if you were to prompt Midjourney to generate images of people in an educational setting, women would show up more than men. This would also be the case when asked to portray someone doing household chores. In contrast, men would be more often portrayed in office settings.
Another example of poor data quality impairing language models is not diverse enough (or “narrow”) data. While it is OK to train a use case-specific model, insufficient data may lead to the model not being able to generalize well to new and diverse examples. This can lead to the model missing essential patterns and relationships in the data, leading to faulty predictions.
Next, and arguably the most difficult to fix, is the poor data quality arising from simply incorrect data. For instance, if the training data contains wrong labels and inconsistent
annotations, it will negatively impact the model’s performance.
In sum, data quality has a significant impact, but it’s often neglected by teams (or considered low-prestige hanging fruit to solve).

Deep Lake-powered machine learning infrastructures help teams quickly address all these problems. It empowers the implementation of a flywheel-based setup for teams that do not have Tesla-grade infrastructure-building capabilities.
One can utilize Deep Lake to complete the first training loop, ingest new data, visualize it with all the metadata, and query to explore under-performing samples (as well as create a complete data lineage to track the dataset evolution as you try to evaluate and improve model performance).
- Multimodality. Dall-E, Stable diffusion, or Whisper all deal with multimodal data. Multimodal data comes from multiple sources and can be represented in different modalities, such as text, images, and audio. This data type can be challenging for language models, as they often need help to process and integrate information from multiple modalities effectively. For example, consider a scenario where you want to classify an image of a dog as either a “Golden Retriever” or a “Labrador Retriever.” A language model trained on text data might need help with this task, as it has a greater understanding of the visual characteristics that distinguish these two breeds.
On the other hand, a computer vision model trained on image data would perform well. However, if the task requires image and text data, such as labeling an image with a caption, combining the two models might perform better than desired. Further work on extending scaling laws for generative mixed-modal language models has been done by Aghajanyan et al. from Meta AI.
- Compute resource shortage. The recent surge of deploying both large language and stable diffusion models caused GPU shortage across major clouds. It fails to allocate resources whenever you try to spin up a p4d.24xlarge with 8xA100 GPUs on AWS. Sometimes you can find resources across different states compared to where your data is stored. That’s where streaming data across regions using Deep Lake shines the most. Deep lake lets you save compute cycles on copying the data, especially when Activeloop-managed software has no egress fees.
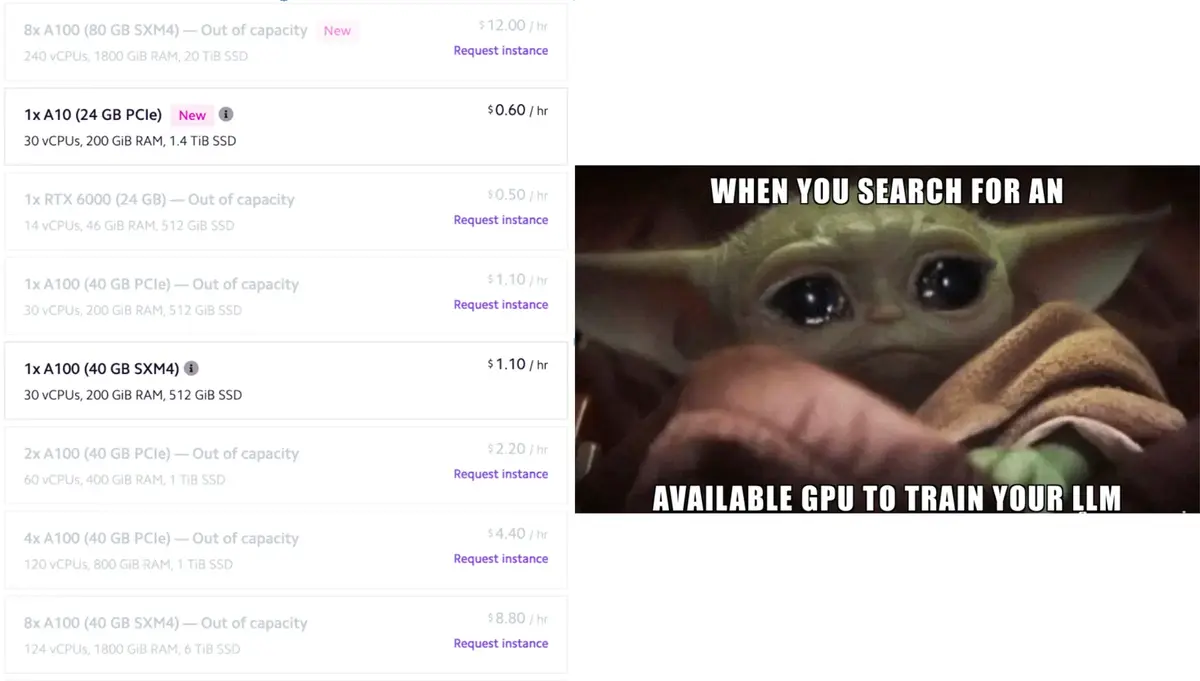
- Deployment and maintenance costs: Once you’re finished training your model, the cost of deployment becomes an issue. For example, Azure charges $3 per hour for one A100 GPU; to operate on one GPT 3.5 model, at least eight GPUs are required. So, when ChatGPT generates a response with an average length of 30 words, it will cost almost 1 cent for the company. OpenAI’s daily operating costs could be at least $100,000 or $3 million per month for serving 1M users and 100 times more for (estimated) 100M users. Serving LLMs is computationally very expensive. It is less likely that services based on LLMs will stay free as the search (especially with the estimated capital expenditure costs nearing $100B for a Google-like deployment working on real-time data).
The reason why Open AI would prefer to keep the service free of charge as long as financially possible is to collect an immense amount of valuable data to re-train models. LLM deployment requires collecting data and storing the data in a ready-to-train format to close the data flywheel. Deep Lake’s Tensor Storage format with native multi-branch version control provides the necessary data infrastructure to store and operate on the data.
Sometimes LLMs require interacting with the database on-the-fly before the output. To serve real-time data, executing embedding search is necessary to retrieve relevant data sources and use LLM capability to summarize the output comprehensively. Deep Lake Tensor Query Language can quickly search for pertinent information feedback during the production or fine-tuning stage of LLMs.
Large Language Model example: how to train NanoGPT with Deep Lake streamable dataloader
NanoGPT architecture breakdown
Recently, Andrej Karpathy released the easiest, swiftest repository for training & fine-tuning medium-sized GPTs called NanoGPT. All-in-all, the code to train the model is a 300-line boilerplate training loop and a 300-line GPT model definition completing GPT2. The model is relatively small, with 126M parameters. Thus, it is mainly bottlenecked by data feeding into GPUs. In contrast, data feeding becomes less of a bottleneck for larger models. Andrej implements the dataloader by loading memory-mapped NumPy arrays of preprocessed tokens from the local file system on top of NVMe into system memory. Then get_batch function randomly samples from it. In short, there is no way to make it faster aside from directly shipping the data to the GPUs (looking at you, GPUDirect!).
1 # poor man's data loader
2data_dir = os.path.join('data', dataset)
3train_data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')
4val_data = np.memmap(os.path.join(data_dir, 'val.bin'), dtype=np.uint16, mode='r')
5def get_batch(split):
6 data = train_data if split == 'train' else val_data
7 ix = torch.randint(len(data) - block_size, (batch_size,))
8 x = torch.stack([torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix])
9 y = torch.stack([torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix])
10 if device_type == 'cuda':
11 # pin arrays x,y, which allows us to move them to GPU asynchronously (non_blocking=True)
12 x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)
13 else:
14 x, y = x.to(device), y.to(device)
15 return x, y
16
In this practical example, we’ll achieve the same performance while streaming the data over the network 🤯. We replace the (ultrafast) local “poor man’s data loader” with Deep Lake’s streamable data loader in NanoGPT while maintaining the full GPU power utilization when data is streamed from US-East to US-West instead of reading from a local file.
OK, you may say, technically, the replacement works. But why should you care? Well, thanks to Deep Lake, you can continuously feed data into the data flywheel by:
Ensuring that preprocessing for 5 hours is avoided after one team member shares the dataset and everyone has a single view of the data.
Enabling dataset querying for curation purposes and troubleshooting model performance on edge cases such as car detection in rainy conditions.
Being able to conduct advanced just-in-time transformations (i.e., normalizing images) since loading is optimized for large volumes of data to leave sufficient bandwidth for that action.
Handling different data locations and computing with no GPU time is spent moving the data around (in case computing power becomes limited on a given platform).
Finally, as data grows, you are no longer limited to local NVMe storage, which is very expensive.
Step-by-step training guide for Large Language Models with Deep Lake
Let’s get hands-on. Full code is available here.
First of all, we define the necessary functions for constructing the dataloader.
OpenWebText dataset creation
To construct the OpenWebText dataset, we create ./data/deeplake/prepare.py
1# define the dataset
2ds = deeplake.empty(path, overwrite=True)
3
4ds.create_tensor('text', htype="text", chunk_compression='lz4')
5ds.create_tensor('tokens', dtype=np.uint16, chunk_compression='lz4')
6
7@deeplake.compute
8def tokenize(example, ds):
9 ids = enc.encode_ordinary(example) # encode_ordinary ignores any special tokens
10 ids.append(enc.eot_token) # add the end of text token, e.g. 50256 for gpt2 bpe
11 ds.append({"text": example, "tokens": np.array(ids).astype(np.uint16)})
12
13# we now want to tokenize the dataset. first define the encoding function (gpt2 bpe)
14
15tokenize().eval(split_dataset[split]['text'], ds, num_workers=num_proc, scheduler="processed")
16ds.commit()
17ds.summary()
18
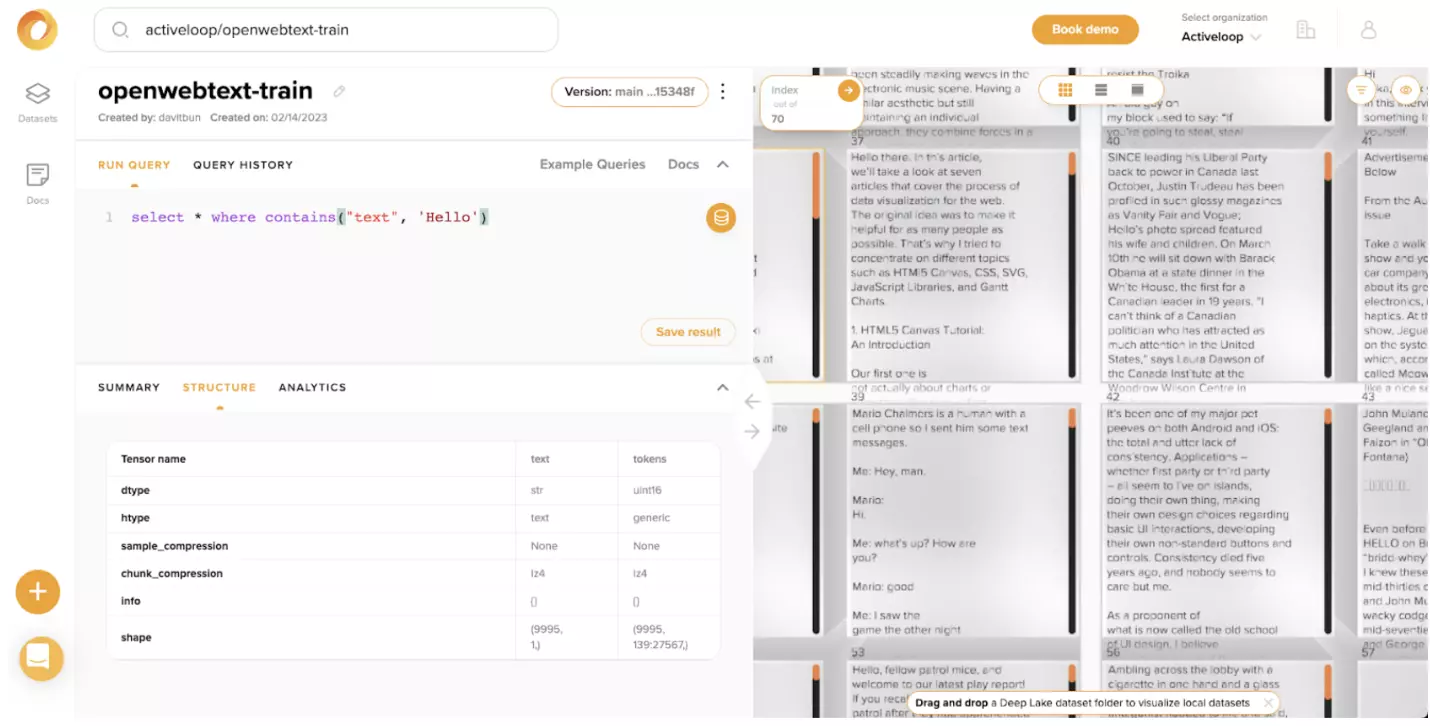
You can explore the OpenWebText training dataset on your own in our UI.
Replacing the dataloader
We will proceed by replacing the dataloader with Deep Lake.
For starters, let’s define collate_fn that would do the batching and local sampling. To avoid undersampling, we add a coefficient to fetch twice more data.
1def collate_fn(data: List[np.ndarray]) -> Tuple[torch.Tensor, torch.Tensor]:
2 """ Collate function samples from a batch of documents """
3 #concatenate all the tokens from the batch
4 data = [d['tokens'] for d in data]
5 data = np.concatenate(data, axis=0)
6
7 #sample a random block of from concatenated documents
8 ix = torch.randint(max(len(data) - block_size, 1), (batch_size,))
9 local_block_size = min(block_size, len(data)-1)
10
11 x = torch.stack(
12[torch.from_numpy((data[i:i+local_block_size]).astype(np.int64)) for i in ix])
13 y = torch.stack(
14[torch.from_numpy((data[i+1:i+1+local_block_size]).astype(np.int64)) for i in ix])
15 return x, y
16
17def get_dataloader(split: deeplake.Dataset, shuffle: bool = False, coef: float = 2, num_workers: int = 1):
18""" Returns a dataloader for the given split. Uses fast enterprise dataloader if available"""
19return dataloader(split)\
20 .batch(int(coef*batch_size), drop_last=True)\
21 .shuffle(shuffle)\
22 .pytorch(num_workers=num_workers, tensors=['tokens'], collate_fn=collate_fn, distributed=ddp)
23
We now load the dataset, checkout to a specific branch if necessary, where token tensor is available, then create train-val split and define iterators get_batch function.
1ds = deeplake.load(dataset, read_only=True, token=token)
2ds.checkout(branch)
3
4meta_vocab_size = None
5
6n_tokens = sum(ds._tokens_shape.numpy())
7print(f'There are ~{n_tokens[0]//10**9}B tokens in the dataset')
8
9split = int(len(ds)*train_split_ratio)
10dl = {
11 "train": get_dataloader(ds[:split], shuffle=shuffle, num_workers=num_workers),
12 "val": get_dataloader(ds[split:], shuffle=False, num_workers=1)
13}
14dl_iter = {"train": dl["train"].__iter__(), "val": dl["val"].__iter__()}
15
And finally, run with
1$ python3 train.py --dataset="hub://activeloop/openwebtext-train"
2
Or with Distributed Data Parallel
1$ torchrun --standalone --nproc_per_node=8 train.py --dataset="hub://activeloop/openwebtext-train"
2
As we can see below, GPUs are 99-100% utilized. A much better metric to track is the energy consumption at full capacity (sometimes 456W/400W 👀). It achieves an avg. of 914MBit/s data streaming from Deep Lake storage into a single 8xA100 machine, preserving the same Model Flops Utilization of 41% from peak bfloat16 as from directly reading from system memory. Each GPU just gets two CPU workers to preload the data. While streaming from cloud providers, we should be careful of egress costs; Activeloop managed storage comes without egress fees.
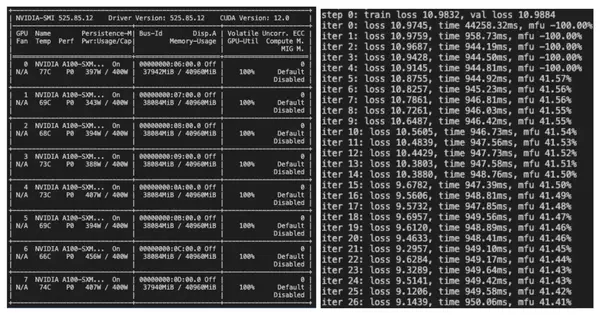
Despite the shortage, we thank Lambda Cloud for providing GPUs to run the experiments. We can observe at least three times cost efficiency compared to major clouds while combining Deep Lake with Lambda Cloud for training large language models.
Concluding remarks
In summary, we discussed the increasing popularity of Large Language Models. As we expect an influx of new multi-modal models in 2023, it is essential to realize that most companies will gain from training their domain-specific LLMs. Doing so would allow for a more accurate and effective interpretation of specialized language, which should routinely beat more general LLMs at their predictions. More importantly, cost-efficiency, UX, and faster go-to-market for LLM-based solutions will be defining for many companies (thus, maintaining a lean training and dataset budget with the help of streaming is in your best interest).
One should also remember that data, not size, is now the primary constraint on language modeling performance. To address this, companies must build a scalable data flywheel to efficiently acquire, retrain, and evaluate data to improve LLM performance. The article also highlighted common issues with LLM training, including data storage and retrieval bottlenecks, and suggested using a Deep Lake - the data lake optimized for deep learning as a solution. Finally, the article acknowledges the ethical and societal implications of using LLMs and calls for their responsible use.