



This course is a part of Gen AI 360: Foundational Model Certification, specifically our popular LangChain & Vector Databases in Production course. Join tens of thousands of developers in the course.
What is Retrieval Augmented Generation (RAG) in AI?
Retrieval Augmented Generation, or RAG, is an advanced technique in AI that bridges information retrieval and text generation. It is designed to handle intricate and knowledge-intensive tasks by pulling relevant information from external sources and feeding it into a Large Language Model for text generation. When RAG receives an input, it searches for pertinent documents from specified sources (e.g., Wikipedia, company knowledge base, etc.), combines this retrieved data with the input, and then provides a comprehensive output with references. This innovative structure allows RAG to seamlessly integrate new and evolving information without retraining the entire model from scratch. It also enables you to fine-tune the model, enhancing its knowledge domain beyond what it was trained on.
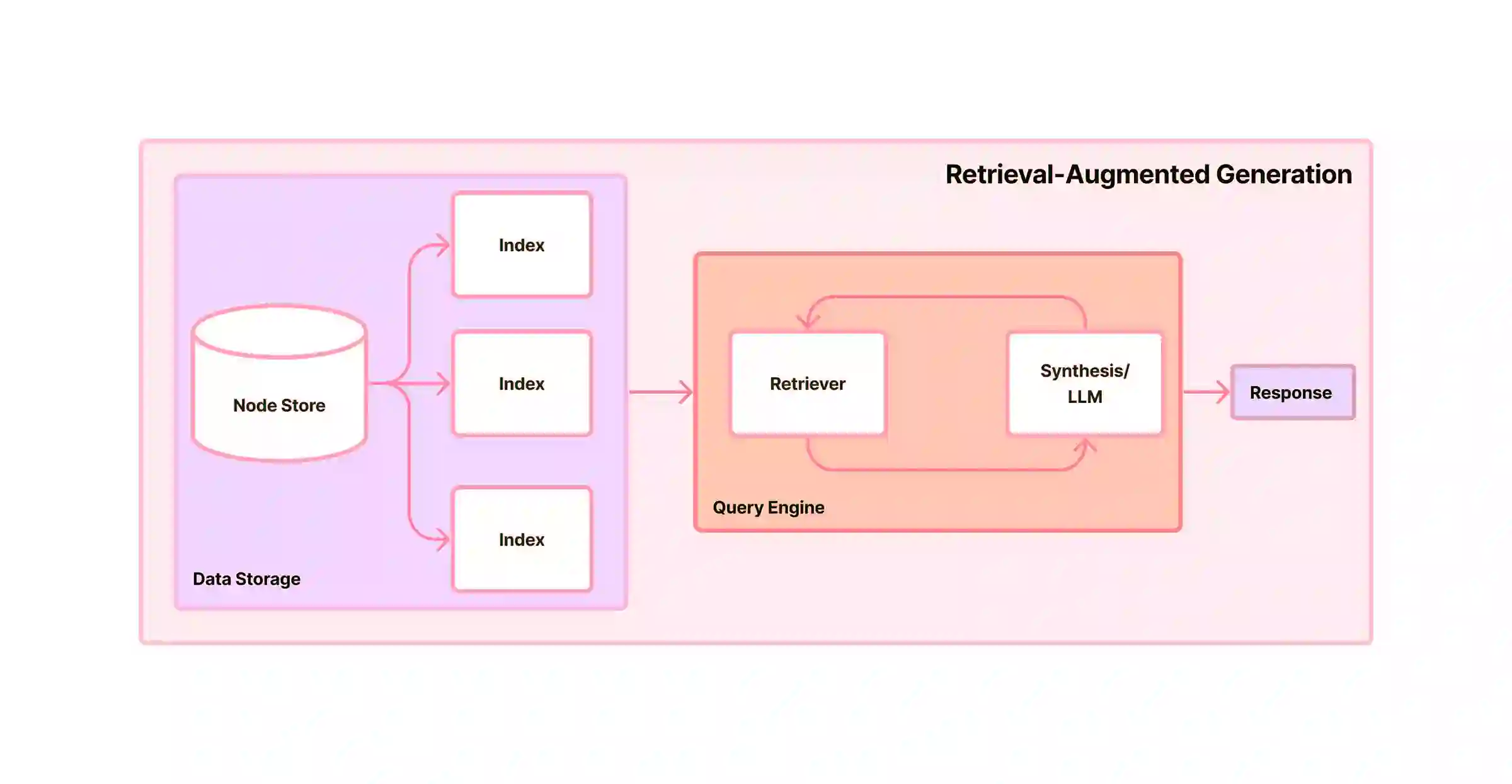
Introduction to Retrieval Augmented Generation (RAG) in AI
Retrieval Augmented Generation (RAG), a new frontier in AI technology, is transforming the digital landscape. With platforms like Cohere & Activeloop, this advanced technology is now easily accessible and customizable, catalyzing a wave of AI-first businesses.
RAG’s impact is considerable. MIT research shows businesses incorporating RAG report up to 50% productivity gains on knowledge-based tasks. By automating mundane tasks, businesses improve resource allocation and employee satisfaction. Notably, Goldman Sachs estimates that such advancements could boost global GDP by 7%.
RAG’s versatility is seen across industries. In customer support, it leads to a 14% productivity increase per hour. In sales, AI-assisted representatives send five times more emails per hour. With the maturation of this technology, these figures will rise even further.
The future of RAG points towards the development of Knowledge Assistants. Acting as intelligent tools for workers, they will retrieve and process corporate data, interact with enterprise systems, and take action on a worker’s behalf. This heralds a new age of AI-driven productivity.
As the third significant revolution in human-computer interfaces, RAG, and LLMs could unlock an estimated $1 trillion in economic value in the U.S. alone. Therefore, businesses and developers must adopt these technologies to remain competitive in the rapidly evolving AI-centric future.
At the end of this article, we cover the Retrieval Augmented Generation History and other fun facts.
Build LLM-powered Chatbot with RAG
To demonstrate the power of Retrieval Augmented Generation for building AI Chatbots with LangChain & Vector Databases, we will build a course companion chatbot for our LangChain & Vector Databases in Production course.
Educational Chatbot harnesses the power of AI to answer queries and provide relevant information to users by retrieving data from an extensive and detailed knowledge base. It returns a natural response to the user’s question and the truth source.
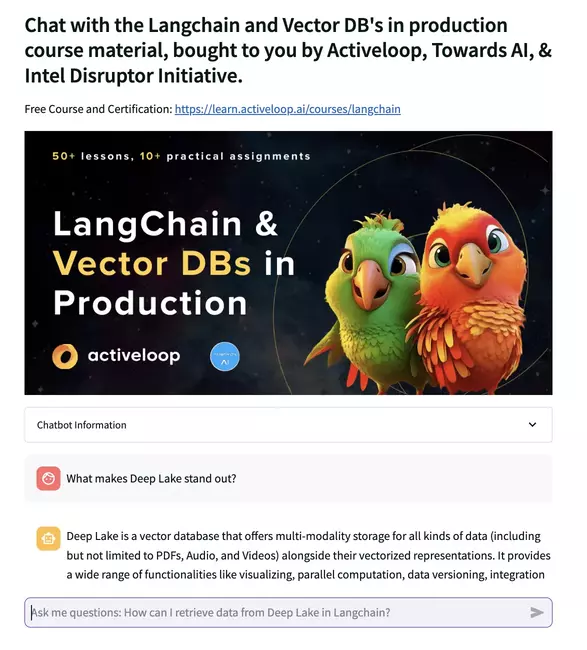
Application Demo: Databutton | LangChain Chat with Deep Lake Vector Database
Application Building Steps:
- Data Loading
- Retrieving Data
- Building Conversation Chain with Memory and Retrieval
- Building the Chat UI
Setting up LangChain & Databutton
LangChain is a standard interface through which you can interact with a variety of large language models (LLMs). It provides modules you can use to build language model applications. It also provides chains and agents with memory capabilities.
The flowchart below demonstrates the pipeline initiated through LangChain to complete the Conversation Process. The tutorial goes into each of the steps in the pipeline, this visual helps to give you an overview of how the components are working together and in what order.
The design pattern started by thinking about the following:
- What problem am I trying to solve?
- Who is going to benefit from this solution?
- How am I going to get and pre-process my data sources?
- How am I going to store and retrieve my data sources?
- How is the user going to interact with my data sources?
Taking a step back before building a solution can really help to save time and importantly considers your end user.
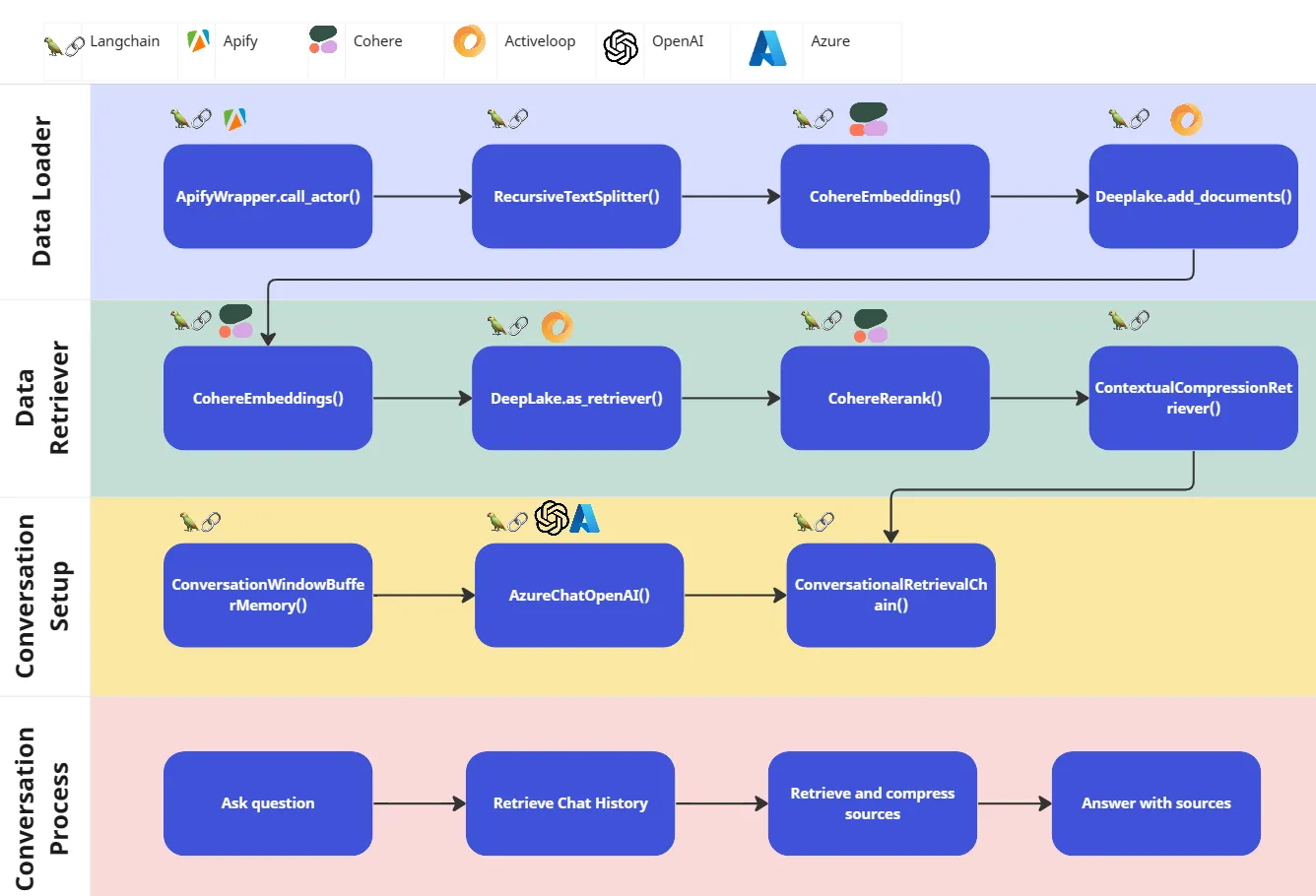
Learning Material and Resources
In order to build this sophisticated Retrieval Augmented Chatbot, I undertook a comprehensive educational journey that includes courses from the ‘LLM University by Cohere’ and ‘LangChain & Vector Databases in Production’.
Application Platform and Required API Keys
Databutton: All-in-one app workspace where we will build and deploy our application. $25 free monthly quota (covers one app a month), community and student plans available.
Cohere API key: Generative AI endpoint for embeddings, rerank and chatbot. Get free, rate-limited usage for learning and prototyping. Usage is free until you go into production
Apify API Key: Web scraping data for the chatbot to retrieve. $5 free usage (more than enough for website contents)
Activeloop token: We will use Deep Lake to store the text scraped from a website. Deep Lake Community version is free to use.
Build your Databutton Application
- Create a free account with Databutton
- Create a new app
Once you have signed up for your free Databutton account, you can create a new app in seconds by clicking on ‘New app’
- Add secrets and packages
- To use the API Key in your app, copy the code snippet from the secret, this will look something like this: ‘COHERE_API_KEY = db.secrets.get(name=”COHERE_API_KEY”)’
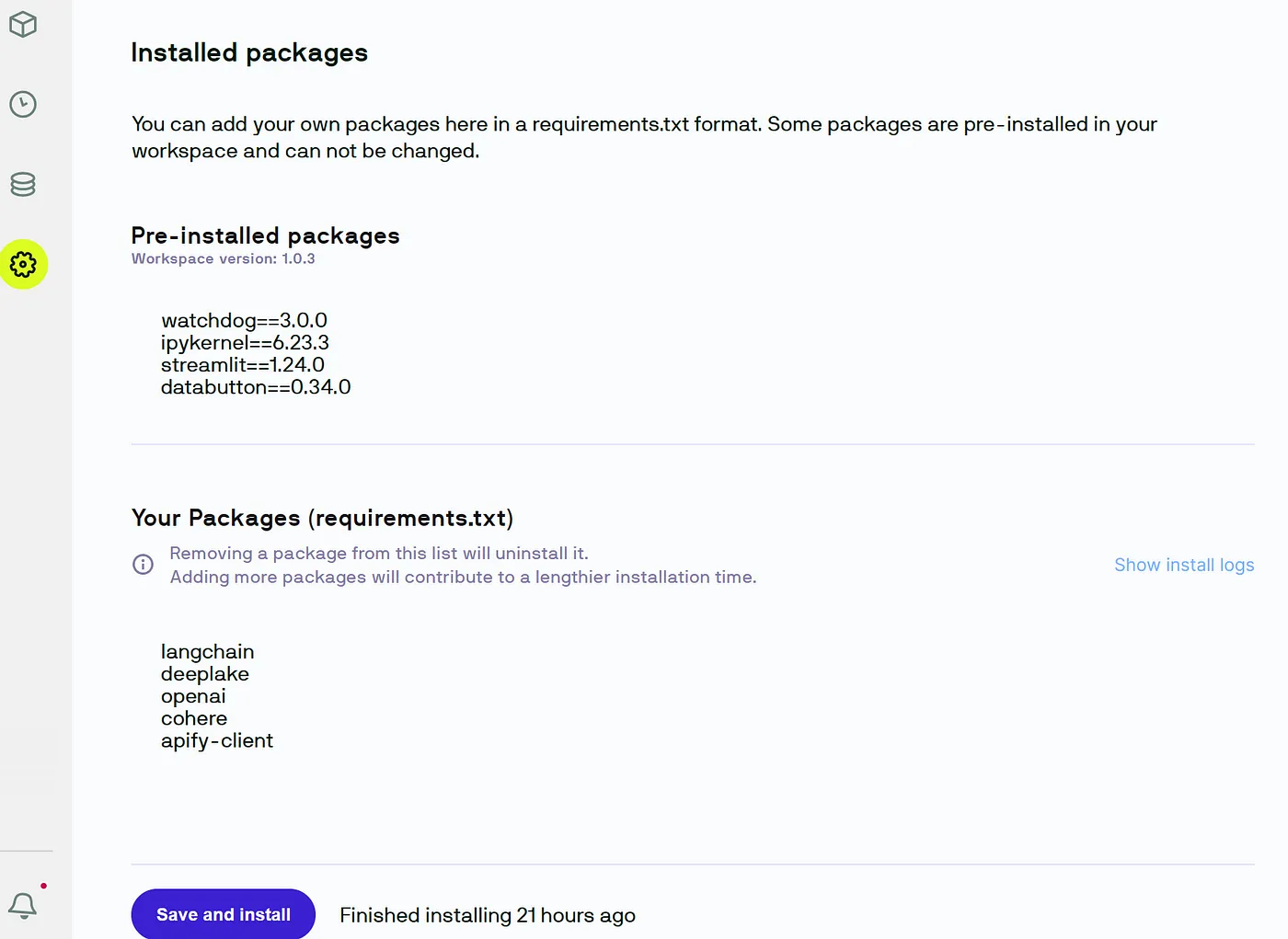
- Add the packages below and click install.
1langchain
2deeplake
3openai
4cohere
5apify-client
6tiktoken
7
- Add entire code from the tutorial to either the Jobs section or the Home Page as specified in the steps below.
Step 1: Loading the Data with RecursiveCharacterTextSplitter
In this stage, we are gathering the data needed to provide context to the chatbot. We use ApifyLoader to scrape the content from a specific website. The RecursiveCharacterTextSplitter is then used to split the data into smaller, manageable chunks. Next, we embed the data using CohereEmbeddings which translates the text data into numerical data (vectors) that the chatbot can learn from. Lastly, we load the transformed data into Deep Lake.
The code for this step is located in the ‘Jobs’ section within Databutton because this is a task that only needs to be run once. Once the data is collected and loaded into DeepLake, it can be retrieved by the chatbot.
Helper Functions
- ApifyWrapper(): Scrapes the content from websites.
1from langchain.document_loaders import ApifyDatasetLoader
2from langchain.utilities import ApifyWrapper
3from langchain.document_loaders.base import Document
4import os
5
6os.environ["APIFY_API_TOKEN"] = db.secrets.get("APIFY_API_TOKEN")
7
8apify = ApifyWrapper()
9loader = apify.call_actor(
10 actor_id="apify/website-content-crawler",
11 run_input={"startUrls": [{"url": "ENTER\YOUR\URL\HERE"}]},
12 dataset_mapping_function=lambda dataset_item: Document(
13 page_content=dataset_item["text"] if dataset_item["text"] else "No content available",
14 metadata={
15 "source": dataset_item["url"],
16 "title": dataset_item["metadata"]["title"]
17 }
18 ),
19)
20
21docs = loader.load()
22
- ApifyWrapperRecursiveCharacterTextSplitter(): Splits the scraped content into manageable chunks.
1from langchain.text_splitter import RecursiveCharacterTextSplitter
2
3# we split the documents into smaller chunks
4text_splitter = RecursiveCharacterTextSplitter(
5 chunk_size=1000, chunk_overlap=20, length_function=len
6)
7docs_split = text_splitter.split_documents(docs)
8
- CohereEmbeddings(): Translates text data into numerical data.
- DeepLake(): Stores and retrieves the transformed data.
1from langchain.embeddings.cohere import CohereEmbeddings
2from langchain.vectorstores import DeepLake
3import os
4
5os.environ["COHERE_API_KEY"] = db.secrets.get("COHERE_API_KEY")
6os.environ["ACTIVELOOP_TOKEN"] = db.secrets.get("APIFY_API_TOKEN")
7
8embeddings = CohereEmbeddings(model = "embed-english-v2.0")
9
10username = "elleneal" # replace with your username from app.activeloop.ai
11db_id = 'kb-material'# replace with your database name
12DeepLake.force_delete_by_path(f"hub://{username}/{db_id}")
13
14dbs = DeepLake(dataset_path=f"hub://{username}/{db_id}", embedding_function=embeddings)
15dbs.add_documents(docs_split)
16
Step 2: Retrieve Data
In this step, we’re setting up the environment to retrieve data from DeepLake using the CohereEmbeddings for transforming numerical data back to text. We’ll then use ContextualCompressionRetriever & CohereRerank to search, rank and retrieve the relevant data.
Add this code to your home page in Databutton
First we set the COHERE_API_KEY and ACTIVELOOP_TOKEN environment variables, using db.secrets.get, allowing us to access the Cohere and ActiveLoop services.
- DeepLake() retrieve data
- CohereEmbeddings()
Following this, we create a DeepLake object, passing in the dataset path to the DeepLake instance, setting it to read-only mode and passing in the embedding function.
Next, we define a data_lake function. Inside this function, we instantiate a CohereEmbeddings object with a specific model, embed-english-v2.0.
- ContextualCompressionRetriever() & CohereRerank()
- Reranking (cohere.com)
We then instantiate a CohereRerank object with a specific model and number of top items to consider (top_n), and finally create a ContextualCompressionRetriever object, passing in the compressor and retriever objects. The data_lake function returns the DeepLake object, the compression retriever, and the retriever.
The data retrieval process is set up by calling the data_lake function and unpacking its return values into dbs, compression_retriever, and retriever.
The Rerank endpoint acts as the last stage reranker of a search flow.
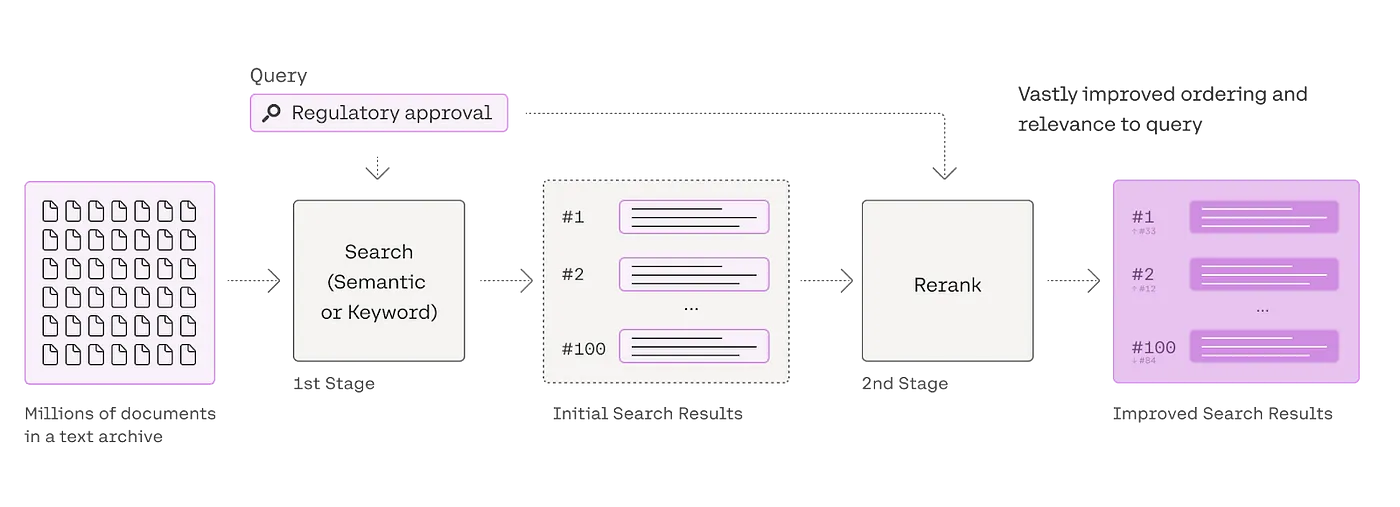
A Brief Intro to Cohere’s Rerank Endpoint for Enhanced Search Results
Within a search process, Cohere’s Rerank endpoint serves as a final step to refine and rank documents in alignment with a user’s search criteria. Businesses can seamlessly integrate it with their existing keyword-based (also called “lexical”) or semantic search mechanisms for initial retrieval. The Rerank endpoint will take over the second phase of refining results.
Cohere’s Rerank & Deep Lake: The Solution to Imprecise Search Outcomes:
This tool is powered by Cohere’s large language model, which determines a relevance score between the user’s query and each of the preliminary search findings. This approach surpasses traditional embedding-based semantic searches, delivering superior outcomes, especially when dealing with intricate or domain-specific search queries.
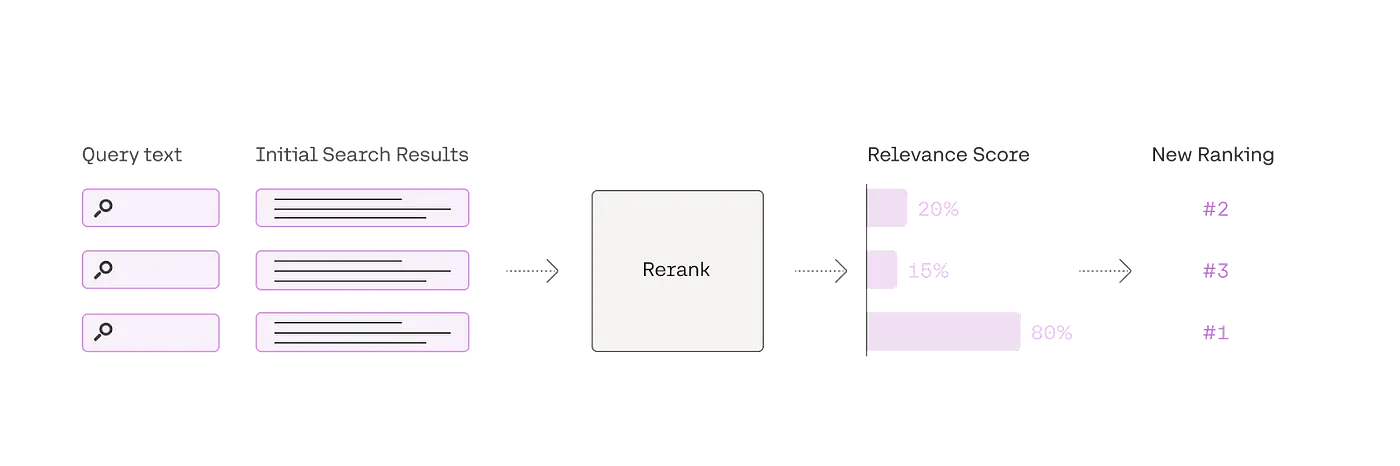
This tool is powered by Cohere’s large language model, which determines a relevance score between the user’s query and each of the preliminary search findings. This approach surpasses traditional embedding-based semantic searches, delivering superior outcomes, especially when dealing with intricate or domain-specific search queries.
The DeepLake instance is then turned into a retriever with specific parameters for distance metric, number of items to fetch (fetch_k), use of maximal marginal relevance and the number of results to return (k).
1from langchain.vectorstores import DeepLake
2from langchain.embeddings.cohere import CohereEmbeddings
3from langchain.retrievers import ContextualCompressionRetriever
4from langchain.retrievers.document_compressors import CohereRerank
5import os
6
7os.environ["COHERE_API_KEY"] = db.secrets.get("COHERE_API_KEY")
8os.environ["ACTIVELOOP_TOKEN"] = db.secrets.get("ACTIVELOOP_TOKEN")
9
10@st.cache_resource()
11def data_lake():
12 embeddings = CohereEmbeddings(model = "embed-english-v2.0")
13
14 dbs = DeepLake(
15 dataset_path="hub://elleneal/activeloop-material",
16 read_only=True,
17 embedding_function=embeddings
18 )
19 retriever = dbs.as_retriever()
20 retriever.search_kwargs["distance_metric"] = "cos"
21 retriever.search_kwargs["fetch_k"] = 20
22 retriever.search_kwargs["maximal_marginal_relevance"] = True
23 retriever.search_kwargs["k"] = 20
24
25 compressor = CohereRerank(
26 model = 'rerank-english-v2.0',
27 top_n=5
28 )
29 compression_retriever = ContextualCompressionRetriever(
30 base_compressor=compressor, base_retriever=retriever
31 )
32 return dbs, compression_retriever, retriever
33
34dbs, compression_retriever, retriever = data_lake()
35
Step 3: Use ConversationBufferWindowMemory to Build Conversation Chain with Memory
In this step, we will build a memory system for our chatbot using the ConversationBufferWindowMemory.
The memory function instantiates a ConversationBufferWindowMemory object with a specific buffer size (k), a key for storing chat history, and parameters for returning messages and output key. The function returns the instantiated memory object.
We then instantiate the memory by calling the memory function.
1@st.cache_resource()
2def memory():
3 memory=ConversationBufferWindowMemory(
4 k=3,
5 memory_key="chat_history",
6 return_messages=True,
7 output_key='answer'
8 )
9 return memory
10
11memory=memory()
12
The chatbot uses the AzureChatOpenAI() function to initiate our LLM Chat model. You can very easily swap this out with other chat models listed here.
1from langchain.chat_models import AzureChatOpenAI
2
3BASE_URL = "<URL>"
4API_KEY = db.secrets.get("AZURE_OPENAI_KEY")
5DEPLOYMENT_NAME = "<deployment_name>"
6llm = AzureChatOpenAI(
7 openai_api_base=BASE_URL,
8 openai_api_version="2023-03-15-preview",
9 deployment_name=DEPLOYMENT_NAME,
10 openai_api_key=API_KEY,
11 openai_api_type="azure",
12 streaming=True,
13 verbose=True,
14 temperature=0,
15 max_tokens=1500,
16 top_p=0.95
17)
18
Next, we build the conversation chain using the ConversationalRetrievalChain. We use the from_llm class method, passing in the llm, retriever, memory, and several additional parameters. The resulting chain object is stored in the qa variable.
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=compression_retriever,
memory=memory,
verbose=True,
chain_type="stuff",
return_source_documents=True
)
Step 4: Building the Chat UI
In this final step, we set up the chat user interface (UI).
We start by creating a button that, when clicked, triggers the clearing of cache and session states, effectively starting a new chat session.
Then, we initialize the chat history if it does not exist and display previous chat messages from the session state.
1# Create a button to trigger the clearing of cache and session states
2if st.sidebar.button("Start a New Chat Interaction"):
3 clear_cache_and_session()
4
5# Initialize chat history
6if "messages" not in st.session_state:
7 st.session_state.messages = []
8
9# Display chat messages from history on app rerun
10for message in st.session_state.messages:
11 with st.chat_message(message["role"]):
12 st.markdown(message["content"])
13
The chat_ui function is used to handle the chat interactions. Inside this function, we accept user input, add the user’s message to the chat history and display it, load the memory variables which include the chat history, and predict and display the chatbot’s response.
The function also displays the top 2 retrieved sources relevant to the response and appends the chatbot’s response to the session state. The chat_ui function is then called, passing in the ConversationalRetrievalChain object.
1def chat_ui(qa):
2 # Accept user input
3 if prompt := st.chat_input(
4 "Ask me questions: How can I retrieve data from Deep Lake in Langchain?"
5 ):
6
7 # Add user message to chat history
8 st.session_state.messages.append({"role": "user", "content": prompt})
9
10 # Display user message in chat message container
11 with st.chat_message("user"):
12 st.markdown(prompt)
13
14 # Display assistant response in chat message container
15 with st.chat_message("assistant"):
16 message_placeholder = st.empty()
17 full_response = ""
18
19 # Load the memory variables, which include the chat history
20 memory_variables = memory.load_memory_variables({})
21
22 # Predict the AI's response in the conversation
23 with st.spinner("Searching course material"):
24 response = capture_and_display_output(
25 qa, ({"question": prompt, "chat_history": memory_variables})
26 )
27
28 # Display chat response
29 full_response += response["answer"]
30 message_placeholder.markdown(full_response + "▌")
31 message_placeholder.markdown(full_response)
32
33 #Display top 2 retrieved sources
34 source = response["source_documents"][0].metadata
35 source2 = response["source_documents"][1].metadata
36 with st.expander("See Resources"):
37 st.write(f"Title: {source['title'].split('·')[0].strip()}")
38 st.write(f"Source: {source['source']}")
39 st.write(f"Relevance to Query: {source['relevance_score'] * 100}%")
40 st.write(f"Title: {source2['title'].split('·')[0].strip()}")
41 st.write(f"Source: {source2['source']}")
42 st.write(f"Relevance to Query: {source2['relevance_score'] * 100}%")
43
44 # Append message to session state
45 st.session_state.messages.append(
46 {"role": "assistant", "content": full_response}
47 )
48
49# Run function passing the ConversationalRetrievalChain
50chat_ui(qa)
51
Verbose Display Code for Streamlit
1import databutton as db
2import streamlit as st
3import io
4import re
5import sys
6from typing import Any, Callable
7
8def capture_and_display_output(func: Callable[..., Any], args, **kwargs) -> Any:
9 # Capture the standard output
10 original_stdout = sys.stdout
11 sys.stdout = output_catcher = io.StringIO()
12
13 # Run the given function and capture its output
14 response = func(args, **kwargs)
15
16 # Reset the standard output to its original value
17 sys.stdout = original_stdout
18
19 # Clean the captured output
20 output_text = output_catcher.getvalue()
21 clean_text = re.sub(r"\x1b[.?[@-~]", "", output_text)
22
23 # Custom CSS for the response box
24 st.markdown("""
25 <style>
26 .response-value {
27 border: 2px solid #6c757d;
28 border-radius: 5px;
29 padding: 20px;
30 background-color: #f8f9fa;
31 color: #3d3d3d;
32 font-size: 20px; # Change this value to adjust the text size
33 font-family: monospace;
34 }
35 </style>
36 """, unsafe_allow_html=True)
37
38 # Create an expander titled "See Verbose"
39 with st.expander("See Langchain Thought Process"):
40 # Display the cleaned text in Streamlit as code
41 st.code(clean_text)
42
43 return response
44
That is all you need to start building your own RAG Chatbot on your own data! I can’t wait to see what you build and how you develop this idea forward.
Conclusion: Retrieval Augmented Generation to Power Chatbots & Economy
In conclusion, Retrieval Augmented Generation (RAG) is not just an emerging AI technology but a transformative force reshaping how businesses operate. With its proven potential to boost productivity, catalyze AI-first businesses, and increase GDP, it’s clear that adopting RAG and Large Language Models is crucial for maintaining a competitive edge in today’s rapidly-evolving digital landscape. The potential of applications like the Educational Chatbot demonstrates how these AI tools can streamline tasks, making operations more efficient and user-friendly. Businesses, developers, and technology enthusiasts need to understand and leverage these advancements. The ongoing development of AI tools like Knowledge Assistants emphasizes the importance of keeping pace with these technological evolutions. As we stand at the brink of the third revolution in human-computer interfaces, we are reminded of the immense value and opportunities RAG and LLMs hold, estimated to unlock $1 trillion in the U.S. economy alone. The future is here, and it’s AI-driven.
Retrieval Augmented Generation FAQs
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation, or RAG, is a machine learning technique combining the best aspects of retrieval-based and generative language models. This method cleverly integrates the strength of retrieving relevant documents from a large set of data and the creative ability of generative models to construct coherent and diverse responses. Moreover, RAG allows the internal knowledge of the model to be updated efficiently without retraining the entire model.
How does Retrieval Augmented Generation work?
RAG operates in two distinct stages. The first stage involves retrieving relevant documents from a vast vector database like Deep Lake using “dense retrieval.” This process leverages vector representations of the query and documents to identify the most relevant document matches. The second stage is the generation phase, where a sequence-to-sequence model is utilized to create a response, considering not just the input query but also the retrieved documents. The model learns to generate responses based on the context of these retrieved documents.
Where is Retrieval Augmented Generation used?
RAG is useful for complex, knowledge-intensive tasks, such as question-answering and fact verification. It has been used to improve the performance of large language models (LLMs) like GPT-4 or LLama-v2, fine-tuning their performance to be more factual, domain-specific, and diverse.
What are Retrieval Augmented Generation advantages?
RAG combines the benefits of both retrieval-based and generative models. This means it gains from the specificity and factual correctness typical of retrieval-based methods while leveraging the flexibility and creativity inherent in generative models. This combination often results in more accurate, detailed, and contextually appropriate responses.
What are the benefits of using Retrieval Augmented Generation
RAG offers several advantages over traditional LLMs:
- RAG can easily acquire knowledge from external sources, improving the performance of LLMs in domain-specific tasks.
- RAG reduces hallucination and improves the accuracy of generated content.
- It requires minimal training, only needing to index your knowledge base.
- RAG can utilize multiple sources of knowledge, allowing it to outperform other models.
- It has strong scalability and can handle complex queries.
- It can overcome the context-window limit of LLMs by incorporating data from larger document collections.
- RAG provides explainability by surfacing the sources used to generate text.
How to implement Retrieval Augmented Generation?
Implementation of RAG involves three key components: a knowledge-base index like Deep Lake, a retriever that fetches indexed documents, and an LLM to generate the answers. Libraries like Deep Lake and LangChain have made it easier to implement these complex architectures.
What is the historical Ccntext of Retrieval Augmented Generation?
Retrieval Augmented Generation, as a concept, has its roots in foundational principles of Information Retrieval (IR) and Natural Language Processing (NLP). Retrieving relevant information before generating a response is common in IR. With the rise of neural network-based models in NLP, these approaches started merging, leading to the development of RAG.
What are the Complexities Involved in RAG?
The main challenge with RAG lies in its dual nature - retrieval and generation. The retrieval phase requires an efficient system to sift through vast data. On the other hand, the generation phase needs a model capable of constructing high-quality responses. Both phases require significant computational resources and advanced machine-learning expertise. Using libraries like Deep Lake for efficient data storage and retrieval helps streamline using RAG.
What are the Current Challenges with Retrieval Augmented Generation?
Current challenges with RAG include:
- Handling complex queries that require deep understanding.
- Managing computational resources efficiently.
- Ensuring response relevance and quality.
- Improving these aspects would make RAG even more effective in tasks like chatbots, question-answering systems, or dialogue generation.