



How to Conduct Multimodal Search with ImageBind & Deep Lake?
If you’ve ever thought that Multimodality in AI is limited to generating images with Midjourney or Dall-E, think again. Multimodal use cases will increasingly become more prevalent, with each additional modality unlocking incremental business value.
In this guide, we’ll explore the creation of a search engine that retrieves AI-generated images using text, audio, or visual inputs, opening new doors for accessibility, user experience, and business intelligence.
To achieve this, we will leverage ImageBind by Meta AI, a game-changer for multimodal AI applications. It captures diverse data modalities and maps them into a common vector space, making our search more powerful. This unlocks novel use cases beyond a vanilla image similarity search.
Unlike anything else, Deep Lake by Activeloop enables the storage and querying of multimodal data (not only the embeddings but also the raw data!). With Deep Lake and ImageBind, the potential applications of this technology are vast. Whether improving product discovery in eCommerce, streamlining digital media libraries, enhancing accessibility in tech products, or powering intuitive search in digital archives, this innovation can drive user satisfaction and business growth.
Let’s build the AI Image Search App!
We need four things: data, a way to generate embeddings, a vector database to store them, and an interactive app. Let’s start with the data. You can also take a look at the article companion video below and fork the GitHub repo as well.
Gathering AI-Generated Images from Lexica for AI Image Search
We were thinking about interesting data to search on, so we came across a the Lexica dataset containing images from Lexica - a website where you can search for AI generate (mostly Stable Diffusion) images. The image search works by exact match in the prompt, while we will create a semantic search.
Since we want to display the images on the web app, we need to get them and store them somewhere (in our case, an S3 bucket - but since Deep Lake is serverless, you can do it wherever). So, first, we load the hugging face dataset
1# pip install datasets
2from datasets import load_dataset
3
4dataset = load_dataset("xfh/lexica_6k", split="train")
5
Then we store each image on a disk.
1for row in dataset:
2 image = row["image"]
3 name = row["text"]
4 image.save(f"{row[name]}.jpg")
5
This is a simplified version. For speed, we used a thread pool on dataset batches. Then we stored the images in a S3 bucket to show them later on the app.
Create Image Embeddings for Multimodal Retrieval
To search the images given a query, we need to encode the images in embeddings, then encode the query and perform cosine similarity to find the “closets,” aka “most similar” images. We want to search using multiple modalities, text, images, or audio. For this reason, we decided to use the new Meta model called ImageBind. If you want, you can learn more about generating image embeddings.
What is ImageBind?
In a nutshell, ImageBind is a transformer-based model trained on multiple pairs of modalities, e.g., text-image, and learns how to map all of them in the same vector space. This means that a text query "dog" will be mapped close to a dog image, allowing us to search in that space seamlessly. The main advantage is that we don’t need one model per modality, like in CLIP where you have one for text and one for image, but we can use the same weights for all of them. The following image taken from the paper shows the idea.

The model supports images, text, audio, depth, thermal, and IMU data. We will limit ourselves to the first three. The task of learning similar embeddings for similar concepts in different modalities, e.g., “dog” and an image of a dog, is called alignment. The ImageBind authors used a Vision Transformer (ViT) , a typical architecture these days. Due to the number of different modalities, the preprocessing step is different. For example, for videos, we need to consider the time dimension, the audio needs to be converted to a spectrogram, but the main weights are the same.

To learn to align pairs of modalities (text, image), (audio, text), the Authors used contrastive learning and specifically the InfoNCE loss. Using InfoNCE, the model is trained to identify a positive example from a batch of negative ones by maximizing the similarity between positive pairs and minimizing the similarity between negative ones.
The most exciting thing is that even if the model was trained on pairs (text, image) and (audio, text), the model also learns (image, audio). This is what the Authors called the “Emergent alignment of unseen pairs of modalities”/
Moreover, we can do Embedding space arithmetic, adding (or subtracting) multiple modalities embeddings to capture different semantic information. We’ll play with it later on.

For the most curious reader, you can learn more by reading the paper
Okay, let’s get the image embeddings. We need to load the model and store the embeddings for all the images, so we can, later on, read them and dump them in the vector database.
Getting the embeddings is quite easy with the ImageBind code code.
1import data
2import torch
3from models import imagebind_model
4from models.imagebind_model import ModalityType
5
6text_list=["A dog.", "A car", "A bird"]
7image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
8audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
9
10device = "cuda:0" if torch.cuda.is_available() else "cpu"
11
12# Instantiate model
13model = imagebind_model.imagebind_huge(pretrained=True)
14model.eval()
15model.to(device)
16
17# Load data
18inputs = {
19 ModalityType.TEXT: data.load_and_transform_text(text_list, device),
20 ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
21 ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
22}
23
24with torch.no_grad():
25 embeddings = model(inputs)
26
27print(embeddings[ModalityType.VISION])
28print(embeddings[ModalityType.AUDIO])
29print(embeddings[ModalityType.TEXT])
30
We first store all the image embeddings as pth files on disk using a simple function to batch the images. Note that we store a dictionary to add metadata; we are interested in the image_path and will use it later.
1@torch.no_grad()
2def encode_images(
3 images_root: Path,
4 model: torch.nn.Module,
5 embeddings_out_dir: Path,
6 batch_size: int = 64,
7):
8 # not the best way, but the faster, best way would be to use a torch Dataset + Dataloader
9 images = images_root.glob("*.jpeg")
10 embeddings_out_dir.mkdir(exist_ok=True)
11 for batch_idx, chunk in tqdm(enumerate(chunks(images, batch_size))):
12 images_paths_str = [str(el) for el in chunk]
13 images_embeddings = get_images_embeddings(model, images_paths_str)
14 torch.save(
15 [
16 {"metadata": {"path": image_path}, "embedding": embedding}
17 for image_path, embedding in zip(images_paths_str, images_embeddings)
18 ],
19 f"{str(embeddings_out_dir)}/{batch_idx}.pth",
20 )
21
Note that a better solution would have been using torch Dataset + Dataloader, and we dive into this in this image embedding tutorial.
How to Store Embeddings in a Vector Database?
After we have obtained our embeddings, load them into Deep Lake. You can learn more about Deep Lake in Deep Lake docs.
To start, we need to define the vector database.
1import deeplake
2
3ds = deeplake.empty(
4 path="<hub://<YOUR_ACTIVELOOP_ORG_ID>/<DATASET_NAME>",
5 runtime={"db_engine": True},
6 token="<YOUR_TOKEN>",
7 overwrite=overwrite,
8 )
9
We are setting db_engine=True, meaning we won’t store the data on our disk, but we will use the managed Deep Lake database to store the data and run our queries. This comes in handy when developing applications where you need to have compute and data storage separation while keeping data where it matters to you. You can deploy the same setup entirely locally and not send your sensitive data anywhere it’s not supposed to be.
Next, we need to define the shape of the data.
1with ds:
2 ds.create_tensor(
3 "metadata",
4 htype="json",
5 create_id_tensor=False,
6 create_sample_info_tensor=False,
7 create_shape_tensor=False,
8 chunk_compression="lz4",
9 )
10 ds.create_tensor("images", htype="image", sample_compression="jpg")
11 ds.create_tensor(
12 "embeddings",
13 htype="embedding",
14 dtype=np.float32,
15 create_id_tensor=False,
16 create_sample_info_tensor=False,
17 max_chunk_size=64 * MB,
18 create_shape_tensor=True,
19 )
20
Here we create three tensors, one to hold the metadata of each embedding, one to store the images (in our case, this is optional, but it’s cool to showcase), and one to store the actual tensors of our embeddings. Deep Lake stands out from the crowd with this feature.
Then it’s time to add our data. We stored batched embeddings to disk as .pth files if you recall.
1
2def add_torch_embeddings(ds: deeplake.Dataset, embeddings_data_path: Path):
3 embeddings_data = torch.load(embeddings_data_path)
4 for embedding_data in embeddings_data:
5 metadata = embedding_data["metadata"]
6 embedding = embedding_data["embedding"].cpu().float().numpy()
7 image = read_image(metadata["path"]).permute(1, 2, 0).numpy()
8 metadata["path"] = Path(metadata["path"]).name
9 ds.append({"embeddings": embedding, "metadata": metadata, "images": image})
10
11embeddings_data_paths = embeddings_root.glob("*.pth")
12list(
13 tqdm(
14 map(
15 partial(add_torch_embeddings, ds),
16 embeddings_data_paths,
17 )
18 )
19)
20
Here we are just iterating all the embeddings file and adding everything within each one. We can have a look at the data from activeloop dashboard - spoiler alert. It is quite cool. You can also visualize the 3D embedding space (and pick your preferred clustering algorithm).
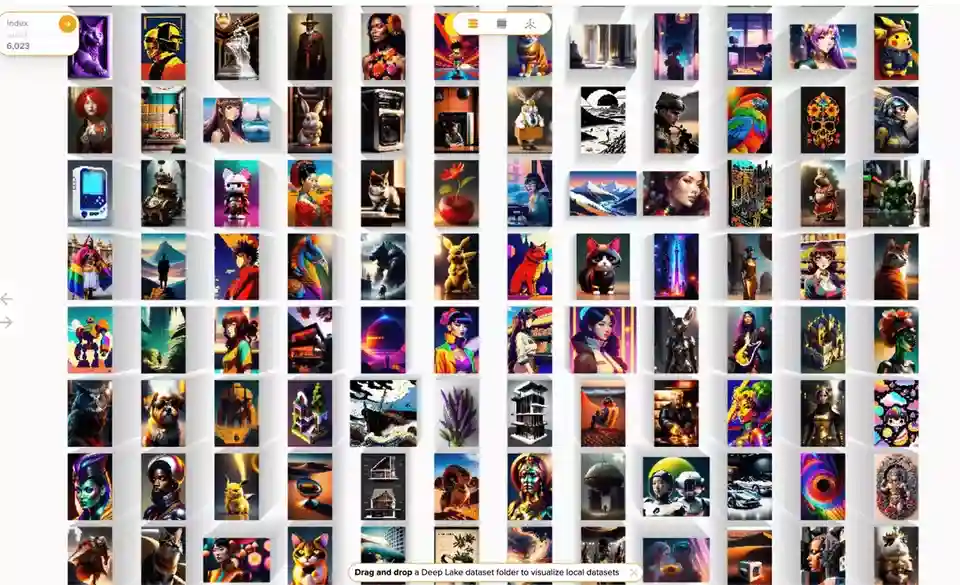
Cool!
To run a query on Deep Lake we can
1embedding = # getting the embeddings from ImageBind
2dataset_path = # our path to active loop dataset
3limit = # number of results we want
4query = f'select * from (select metadata, cosine_similarity(embeddings, ARRAY{embedding.tolist()}) as score from "{dataset_path}") order by score desc limit {limit}'
5query_res = ds.query(query, runtime={"tensor_db": True})
6# query_res = Dataset(path='hub://zuppif/lexica-6k', read_only=True, index=Index([(1331, 1551)]), tensors=['embeddings', 'images', 'metadata'])
7
We can access the metadata by
1query_res.metadata.data(aslist=True)["value"]
2# [{'path': '5e3a7c9b-e890-4975-9342-4b6898fed2c6.jpeg'}, {'path': '7a961855-25af-4359-b869-5ae1cc8a4b95.jpeg'}]
3
If you remember, these are the metadata we stored previously, so the image filename. We wrapped all the vector store-related code into a VectorStore class inside vector_store.py.
1class VectorStore():
2 ...
3 def retrieve(self, embedding: torch.Tensor, limit: int = 15) -> List[str]:
4 query = f'select * from (select metadata, cosine_similarity(embeddings, ARRAY{embedding.tolist()}) as score from "{self.dataset_path}") order by score desc limit {limit}'
5 query_res = self._ds.query(query, runtime={"tensor_db": True})
6 images = [
7 el["path"].split(".")[0]
8 for el in query_res.metadata.data(aslist=True)["value"]
9 ]
10 return images, query_res
11
So, since the model supports text, images, and audio we can also create a utility function to make our life easier.
1@torch.no_grad()
2def get_embeddings(
3 model: torch.nn.Module,
4 texts: Optional[List[str]],
5 images: Optional[List[ImageLike]],
6 audio: Optional[List[str]],
7 dtype: torch.dtype = torch.float16
8) -> Dict[str, torch.Tensor]:
9 inputs = {}
10 if texts is not None:
11 # they need to be ints
12 inputs[ModalityType.TEXT] = load_and_transform_text(texts, device)
13 if images is not None:
14 inputs[ModalityType.VISION] = load_and_transform_vision_data(images, device, dtype)
15 if audio is not None:
16 inputs[ModalityType.AUDIO] = load_and_transform_audio_data(audio, device, dtype)
17 embeddings = model(inputs)
18 return embeddings
19
Always remember the torch.no_grad decorator :) Next, we can easily do
1vs = VectorStore(...)
2vs.retrieve(get_embeddings(texts=["A Dog"]))
3
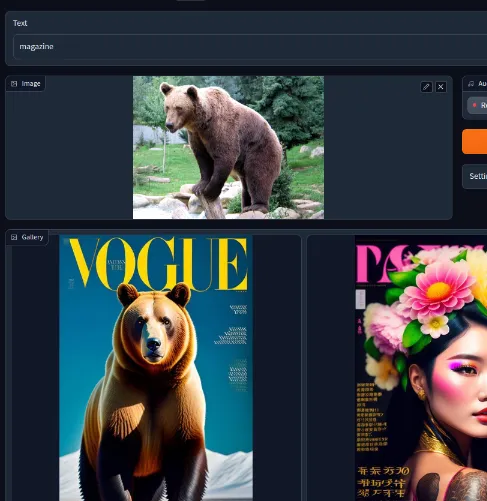
| query | results | ||
| "A Dog" |
|
|
1vs = VectorStore(...)
2vs.retrieve(get_embeddings(texts=["A Car"]))
3
| query | results | ||
| "A Car" |
|
|
Developing an AI Image Search App with Gradio
We’ll use Gradio to create a sleek UI for the app. We’d need first to define the inputs and outputs of the app.
1with gr.Blocks() as demo:
2 # a little description
3 with Path("docs/APP_README.md").open() as f:
4 gr.Markdown(f.read())
5 # text input
6 text_query = gr.Text(label="Text")
7 with gr.Row():
8 # image input
9 image_query = gr.Image(label="Image", type="pil")
10 with gr.Column():
11 # audio input
12 audio_query = gr.Audio(label="Audio", source="microphone", type="filepath")
13 search_button = gr.Button("Search", label="Search", variant="primary")
14 # and a little section to change the settings
15 with gr.Accordion("Settings", open=False):
16 limit = gr.Slider(
17 minimum=1,
18 maximum=30,
19 value=15,
20 step=1,
21 label="search limit",
22 interactive=True,
23 )
24 # This will show the images
25 gallery = gr.Gallery().style(columns=[3], object_fit="contain", height="auto")
26
27
This results in the following UI.
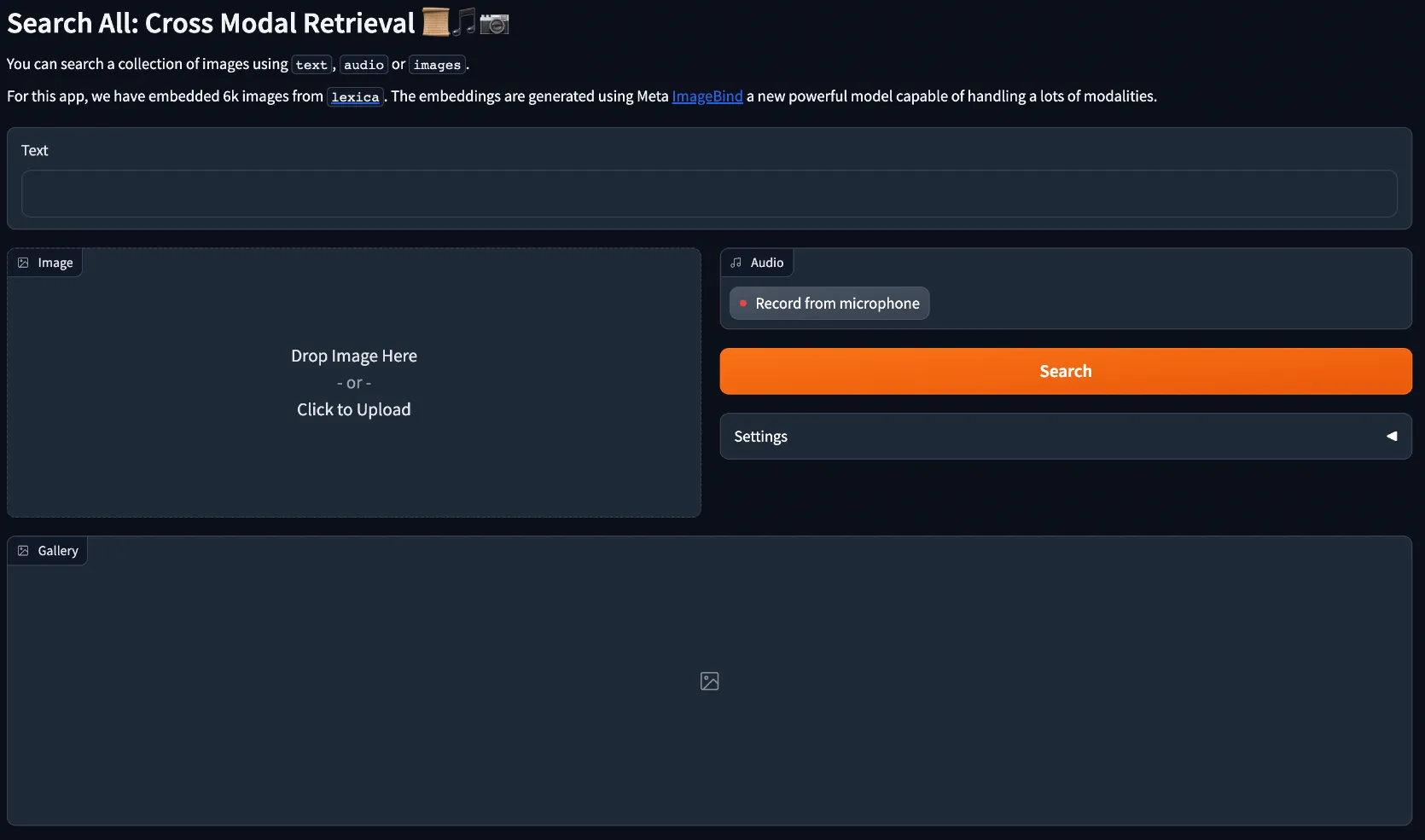
Then we need to link the search button to the actual search code.
1...
2search_button.click(
3 search_button_handler, [text_query, image_query, audio_query, limit], [gallery]
4 )
5
This means text_query, image_query, audio_query, limit are the inputs to search_button_handler and gallery is the output.
where search_button_handler is
1...
2vs = VectorStore.from_env()
3model = get_model()
4...
5def search_button_handler(
6 text_query: Optional[str],
7 image_query: Optional[Image.Image],
8 audio_query: Optional[str],
9 limit: int = 15,
10):
11 if not text_query and not image_query and not audio_query:
12 logger.info("No inputs!")
13 return
14 # we have to pass a list for each query
15 if text_query == "" and len(text_query) <= 0:
16 text_query = None
17 if text_query is not None:
18 text_query = [text_query]
19 if image_query is not None:
20 image_query = [image_query]
21 if audio_query is not None:
22 audio_query = [audio_query]
23 start = perf_counter()
24 logger.info(f"Searching ...")
25 embeddings = get_embeddings(model, text_query, image_query, audio_query).values()
26 # if multiple inputs, we sum them
27 embedding = torch.stack(list(embeddings), dim=0).sum(0).squeeze()
28 logger.info(f"Model took {(perf_counter() - start) * 1000:.2f}")
29 images_paths, query_res = vs.retrieve(embedding.cpu().float(), limit)
30 return [f"{BUCKET_LINK}{image_path}" for image_path in images_paths]
31
So for each input, we check that they exist, if they do, we wrap them into a list. This is needed for our internal implementation. vs.retrieve is a function of VectorStore, just a utility class that wrap all the code in the same place. Inside that function, we first compute the embeddings using the get_embeddings function shown before, and then we run a query against the vector db.
We have stored all the images in S3, so we return a list of links to the images there; this is the input to gr.Gallery
Where that’s it! Let’s see it in action.
Normal single modality works as expected.
If we receive more than one input, we sum them up. Basically,
1embedding = torch.vstack(list(embeddings)).sum(0)
2
For example, we can pass an image of a car and an audio of a f1 race.
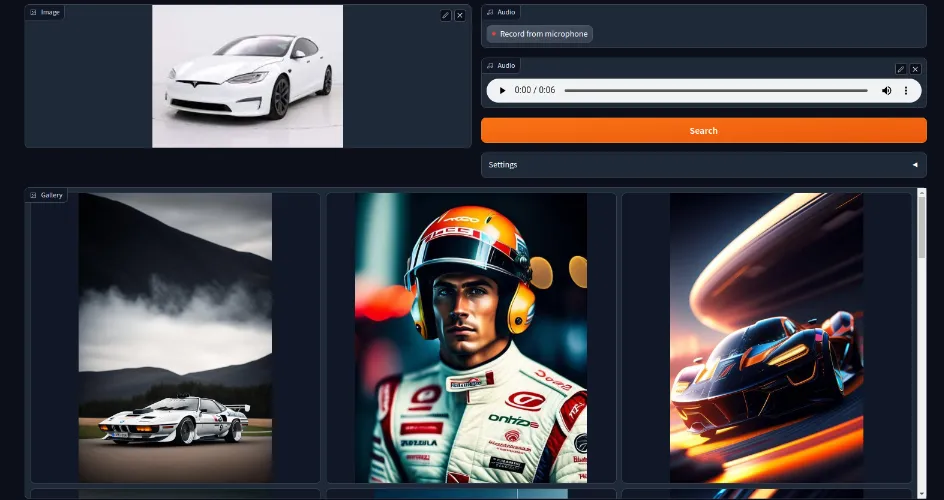
or the text + image. We can also do text + image + audio. Feel free to test it out!
Some of the results were not too great, “cartoon” + cat image.
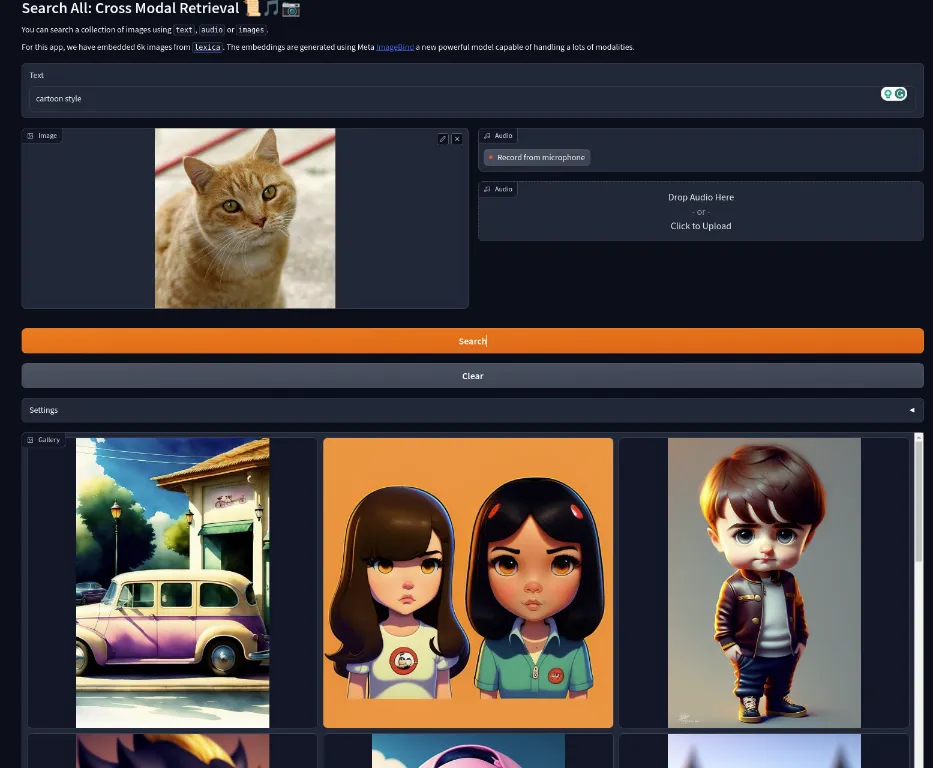
In our experiments, we’ve noticed that the text is more potent compared to image and audio when combined with the other modalities
The Future of Multimodal Search
In conclusion, the fusion of ImageBind and Deep Lake provides a robust framework for developing an AI-based multimodal search engine. By leveraging AI-generated images and text, audio, and visual inputs, we’ve shown how it’s possible to make strides toward more intuitive, efficient, and inclusive search experiences.
For machine learning engineers, this exploration opens up new avenues for creating more user-centric applications. At the same time, business executives can see the transformative impact of AI on a wide array of industries.
The future of search is here, and it’s multimodal. Now it’s your turn. Try the demo and share the results!
ImageBind & Multimodal Search FAQs
What Modalities are Supported by ImageBind?
ImageBind supports six different modalities - images, text, audio, depth, thermal, and IMU data. The modality encoders are based on a Transformer architecture, including the Vision Transformer (ViT) for images and videos. Audio is encoded by converting a 2-second audio sample into spectrograms, which are treated as 2D signals and encoded using a ViT. Thermal images and depth images are treated as one-channel images and also encoded using a ViT.
Is ImageBind Open Source?
ImageBind is an open-source project with a PyTorch implementation and pretrained models available. The model and accompanying weights are available for download and can be used to feed text, image, and audio data into ImageBind.
Is ImageBind Applications?
ImageBind enables novel applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation. It has several potential use cases, including information retrieval, zero-shot classification, and connecting the output of ImageBind to other models. ImageBind could play a crucial role in developing autonomous vehicles, helping them to perceive and interpret their surroundings more effectively.
Who Developed ImageBind?
ImageBind has been developed and open-sourced by researchers at Meta.
What is multimodal AI?
Multimodal AI is an AI category that integrates various types, or modalities, of data to reach more precise conclusions, make insightful deductions, or provide more accurate real-world problem predictions. Multimodal AI platforms use and learn from a variety of data including video, audio, speech, images, text, and numerous traditional structured datasets.
What are the benefits of multimodal AI?
Multimodal AI generally surpasses single modal AI in many real-world situations. Through the combination of different data types, multimodal AI can produce more accurate, human-like responses, thereby enhancing its versatility and adaptability in varying scenarios. Industries like healthcare, finance, and retail could significantly benefit from multimodal AI due to its ability to provide precise and customized responses.
What are the challenges of multimodal AI?
Despite its potential and advantages, multimodal AI does have associated challenges, specifically related to data quality and interpretation for developers. Certain modalities may be excessively noisy, complicating the AI system’s learning process. The complexity of multimodal AI systems necessitates substantial computational resources. Lastly, for these systems to be trusted, they need to be explainable.
What is multimodal machine learning?
Multimodal machine learning is an evolving multidisciplinary research domain aimed at developing computer agents with intelligent capabilities to process and connect information from multiple modalities. There has been considerable progress in this emerging field over recent years.
What are the applications of multimodal AI?
Multimodal AI has extensive applications across various sectors including healthcare, finance, and retail. Multimodal conversational AI systems can answer queries, complete tasks, and mimic human conversations by comprehending and conveying information from multiple modalities. Complex recipe generation from images is another potential application for multimodal AI.
What is the difference between multimodal AI and single modal AI?
The key distinction between multimodal AI and conventional single modal AI lies in the data. Single modal AI is typically designed to handle a singular data source or type. For instance, a financial AI leverages business financial data, along with wider economic and industrial sector data, to conduct analyses, make financial predictions, or identify potential financial issues for the company. In other words, the single modal AI is specialized for a specific task.