



The Problem in RAGs is Inaccurate Retrieval
Enterprises are currently building ‘chat with your data’ applications for a variety of use cases ranging from documenting internal processes to adding automation for customer support. These solutions are typically implemented using Retrieval Augmented Generation (RAG) systems that provide context to Large Language Models (LLMs) like GPT-4. Retrieval Augmented Generation also infuses the model with strategically relevant bits of the latest information, reducing the need to fine-tune the model separately and removing the training dataset restriction. While truthfulness and faithfulness are important, the utility of the implementation ultimately depends on the retrieval accuracy. At best, RAG applications achieve a retrieval accuracy of 70%, so in 30% of cases, an LLM like GPT-4 cannot provide an accurate response to the user’s requests. This level of inconsistency is obvious and perceptible by the end user, and it is unacceptable when applications play a crucial role in business-critical operations.
Existing Solutions Provide Incremental Improvements
There are several options for boosting the accuracy of RAG systems such as: adjusting the input with feature engineering, fine-tuning embeddings, employing hybrid or lexical search, reranking the final results with cross encoders, and context-aware fine-tuning your LLM. However, these techniques offer marginal improvements that do not fundamentally change the user-experience of using LLM apps.
Another approach for increasing accuracy is to use a broader LLM context, but this often results in higher costs with only minor gains. Why?
Answer quality decreases, and the risk of hallucination increases
As shown in a recent study from Stanford, LLMs struggle to pick out key details from large contexts, especially if these details are in the middle. These models find it hard to focus on relevant info when given many documents, and the problem gets worse (up to 20%) with more documents.The bigger the context, the higher the cost for LLM execution.
LLM providers bill based on data size, and adding more data to a query increases the cost. For self-deployments, the cost manifests though higher compute requirements and larger infrastructure.
Introducing Deep Memory: An Actual Solution That Works
Deep Memory significantly increases Deep Lake’s vector search accuracy up to +22% by learning an index from labeled queries tailored to your application, without impacting search time. These results can be achieved with only a few hundred example pairs of prompt embeddings and most relevant answers from the vector store.

Post training, vector search is used without modifications as if normal.
Embeddings can still be computed using a model of your choice such as Open AI ada-002 or other OSS models BGE by BAAI. Furthermore, search results from Deep Memory can be further improved by combining them with lexical search or reranker.
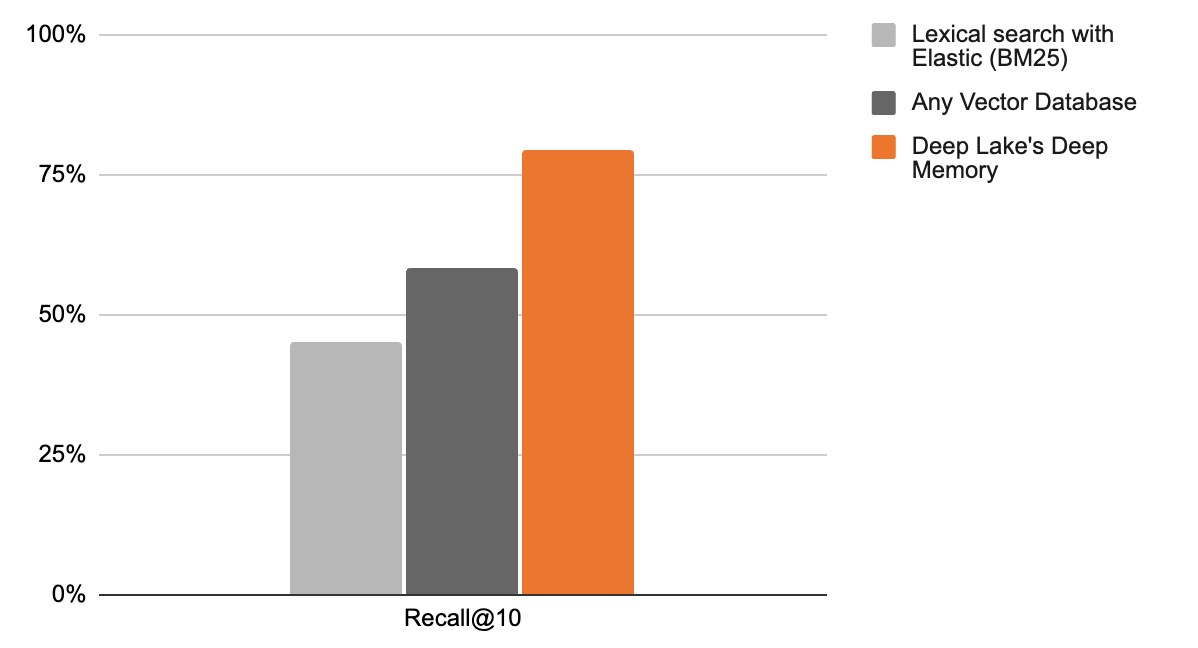
Recall comparison of lexical search, vector search and deep memory at top 10 retrieved documents
How can you do it yourself?
Let’s get hands-on. first, we load the indexed dataset, let’s call it corpus. It has to be in managed database (runtime={"tensor_db": True}) to leverage Deep Memory training on the Deep Lake Managed Tensor Database.
1from deeplake import VectorStore
2
3corpus = VectorStore(
4 "hub://activeloop-test/scifact-demo",
5 embedding_function = embeddings.embed_documents,
6 runtime={"tensor_db": True}
7)
8
Then, we construct a dataset of questions and relevance. Relevance is a set of pairs (corpus.id: str, significance: str) which provides information where is the answer inside the corpus. Sometimes an answer can be found in multiple locations or have different significance. Relevance enables Deep Memory training to correctly optimize the embedding space for higher accuracy. The goal here is to obtain a labelled query dataset similar to what your user would ask in production setting. To observe significant improvements, we would expect to have few hundred query pairs. If you don’t have already labelled query dataset, you can also use GPT4 to generate synthetic pairs based on chunks from the corpus.
Then, we kickstart the training job on the Activeloop platform.
1questions = ["question 1", ...]
2relevance = [[(corpus.dataset.id[0], 1), ...], ...]
3
4job_id = corpus.deep_memory.train(
5 queries = questions,
6 relevance = relevance,
7 embedding_function = embeddings.embed_documents,
8)
9
We can monitor training progress and observe that we received up to +21.5% on validation set in few minutes 🤯.
1corpus.deep_memory.status(job_id)
2

We can directly enable Deep Memory inside vector search without waiting the training to finish.
1corpus.search(
2 embedding_data = "Female carriers of the Apolipoprotein E4 (APOE4) allele have increased risk for dementia.",
3 embedding_function = embeddings.embed_query,
4 deep_memory = True
5)
6
A GPT4 answer based on naive vector search would produce the following result
“The provided context does not explicitly state that female carriers of the Apolipoprotein E4 (APOE4) allele have an increased risk for dementia.”
however with deep memory enabled
“The Apolipoprotein E4 (APOE4) allele is a confirmed susceptibility locus for late-onset Alzheimer’s disease.”
While qualitative results are good for manual inspection, in order to evaluate in a production setting we would like to quantitatively measure the accuracy of the information retrieval on previously unseen queries. This provides objective metrics to compare against naive vector search, or even lexical search.
1corpus.deep_memory.evaluate(
2 queries = test_questions,
3 relevance = test_relevance,
4 embedding_function = embeddings.embed_documents,
5 top_k=[1, 3, 5, 10, 50, 100]
6)
7

X Axis computes recall per top k. Higher recall % and lower K is better.
As you increase k , the likelihood of correct answer appearing in the retrieved results increases. However, since the LLM API costs are proportional to the number of tokens in the context, your goal is to decrease top_k while preserving accuracy. Deep Memory lets you to decrease top_k from 10 to 3 while preserving the accuracy, resulting in up to 70% lower token usage, faster computations, and lower costs.
Customer Spotlight: Munai Boosts Vector Search Accuracy by 41% with Deep Memory

Health tech startup Munai, backed by the Bill & Melinda Gates Foundation, provides intelligent patient management.
“Leveraging Deep Memory, we’ve achieved an astounding 18.6% boost in our vector search accuracy across medical documents. Such a transformation directly impacts the efficiency and efficacy of our solutions.” - Mateus Cichelero da Silva, Data Chapter Lead at Munai
The company collaborates with one of the largest hospitals in Brazil to facilitate patient management for healthcare professionals and health insurance companies.
“Munai is one of the leading innovative generative AI solution providers in Healthcare. We are more than excited to partner with them to deploy mission critical AI workloads into hospitals” - Davit Buniatyan, CEO of Activeloop

Hugo Morales e Cristian Rocha, founders of Munai, healthtech generative AI startup (Crédito: Divulgação)
“Deep Memory marks a groundbreaking advancement in constructing precision-focused RAG systems for medical applications. In contexts as delicate as healthcare environments, this is not just an improvement; it’s a revolution” - Cristian Rocha CEO of Munai
Higher Accuracy at Lower Cost for Your RAG Application
Deep Memory increases retrieval accuracy without altering your existing workflow. Additionally, by reducing the top_k input into the LLM, you can significantly cut inference costs via lower token usage.
Benefits of Deep Memory
- Higher Quality: Accuracy improves up to +22% learning from queries on average, with customers like Munai achieving up to 41% increase.
- Cost Reduction: Saving up to 50% GPT4 cost and execution time by reducing top k.
- Simple to Use: No change in Deep Lake Vector Search usage, same speed with higher accuracy. Natively integrated inside Langchain & LlamaIndex.
- Smaller, Faster, Cheaper: Use smaller text embeddings combined with Deep Memory such as BGE_small (384 dims) to beat OpenAI’s ada-002 (1536 dims) and/or Elastic (BM25).
Get Started Today
A number of enterprise customers are already reaping the benefits of the Deep Memory-powered Retrieval Augmented Generation apps. Dive into the future with our hosted training service in our Managed Tensor Database.
Note: Deep Memory is now generally available with the latest Deep Lake version.